
The Way We Was
I collect anonymous, vernacular photography in 35mm slide form. There’s a lot to like about these artifacts: They show us a snapshot of trends, fashion, haircuts, eyeglass styles, cars, road signs and prices changing over time. Beyond their historical value, they have a warm analog aesthetic that pleases me. This form of anthropology appeals to me because I’m old enough to have vague memories of the subjects.
Images are regularly posted to Bluesky and uploaded to The Internet Archive.
Slides are purchased in lots on eBay, found at estate sales or gifted to me from friends and family. I originally began collecting retro San Francisco slides and slowly expanded to pictures of interesting people.
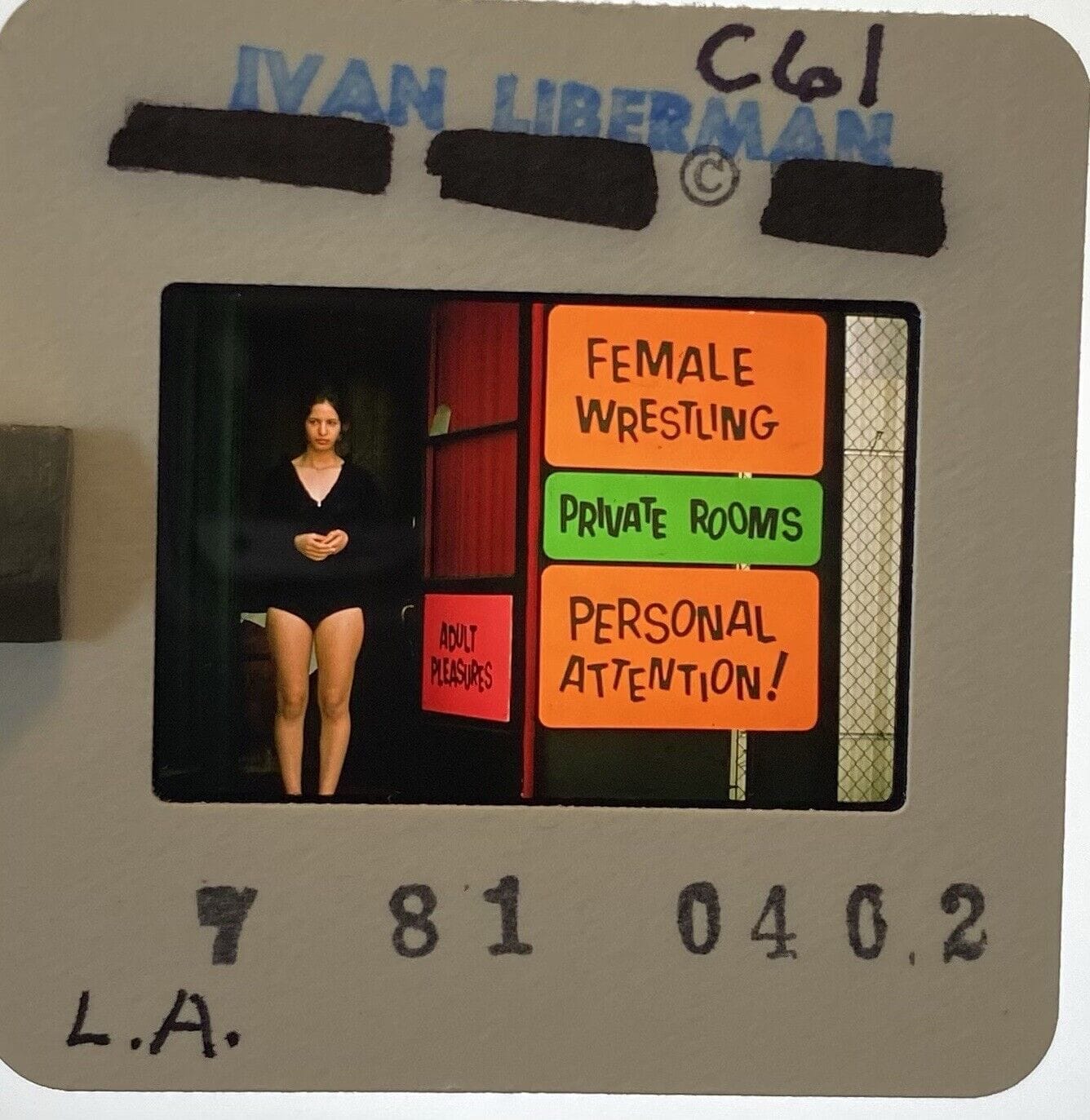


35mm slides
Some of my favorite images so far:



A few of my favorite images
Often times I am uh gifted (as in, “get this junk out of my house”) entire slide collections. This one arrived in its original steel cases:

I make a first pass through a collection by holding an image up to sunlight. If there’s anything at all that intrigues me, I’ll put it in the maybe-pile. For the second pass, I view the slides with a standalone viewer. These are about $30 on Amazon:

Slides that make the final cut are cleaned (brushed and blown) then scanned with a Plustek OpticFilm 8300i hooked up to my Mac. The slide scanner was bundled with QuickScan Plus which will import the images to TIFF files. Thankfully, the software behaves well and can run in the background, allowing me to do other things, while it scans at 3600 DPI.
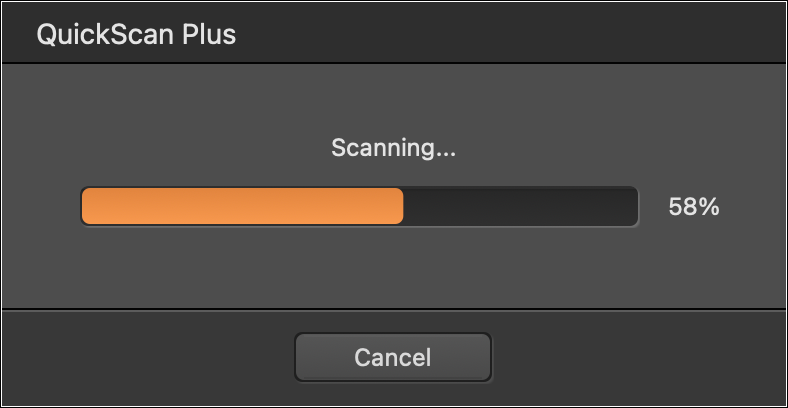
QuickScan Pro will automatically crop images which can be frustrating if they were taken in low light. I eventually discovered that performing a custom scan would allow me to control cropping:
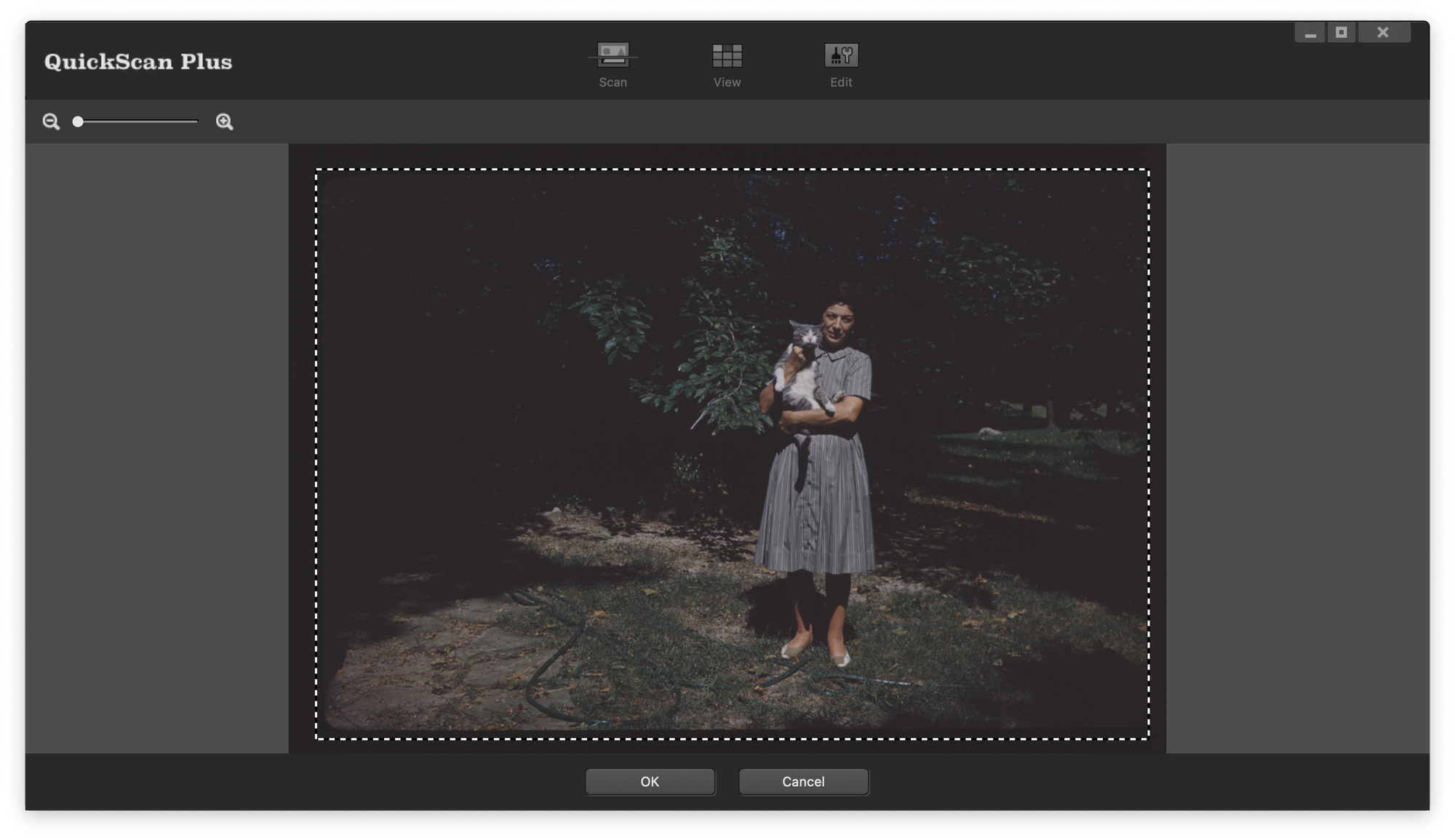
Here’s an example of an un-edited image scanned before dust was removed:

The same image after being brushed and touched up in Photoshop: Auto Tone, Auto Contrast and Auto Color are applied where it looks good.

Prominent scratches and little blotches are still present. Sometimes I will straighten an image’s horizon or correct colors but I won’t do nearly the amount of editing that my own photography requires.
Most images arrive in my collection with no context or additional information. Sometimes slides have the year written on them, sometimes they come from a well-documented set and sometimes their eBay listings will include additional details.

For alt-text and a description of the image, I use ChatGPT’s API to ask for a description of the image(s) and suggest keywords that I can use for hashtags or tagging.
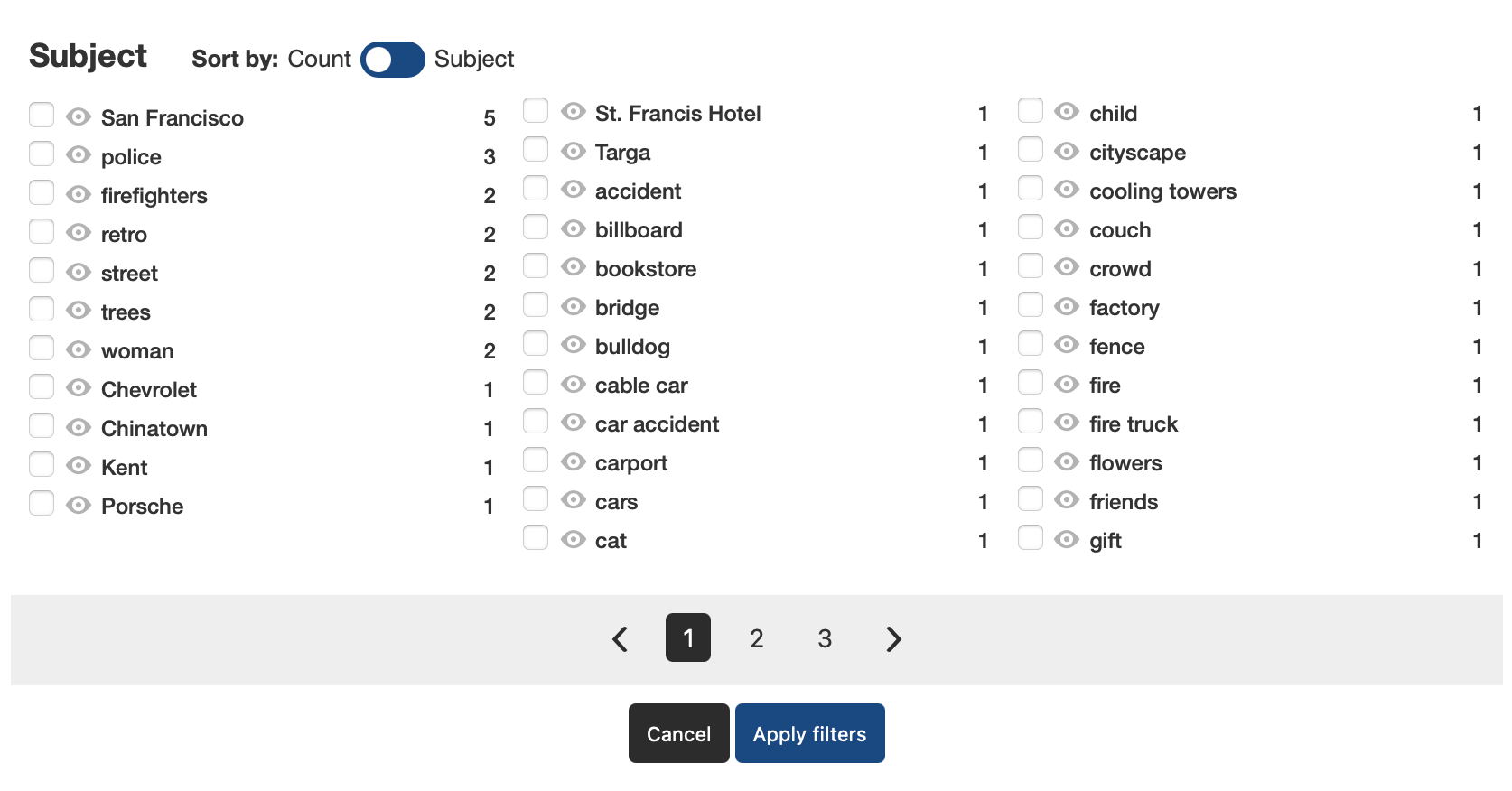
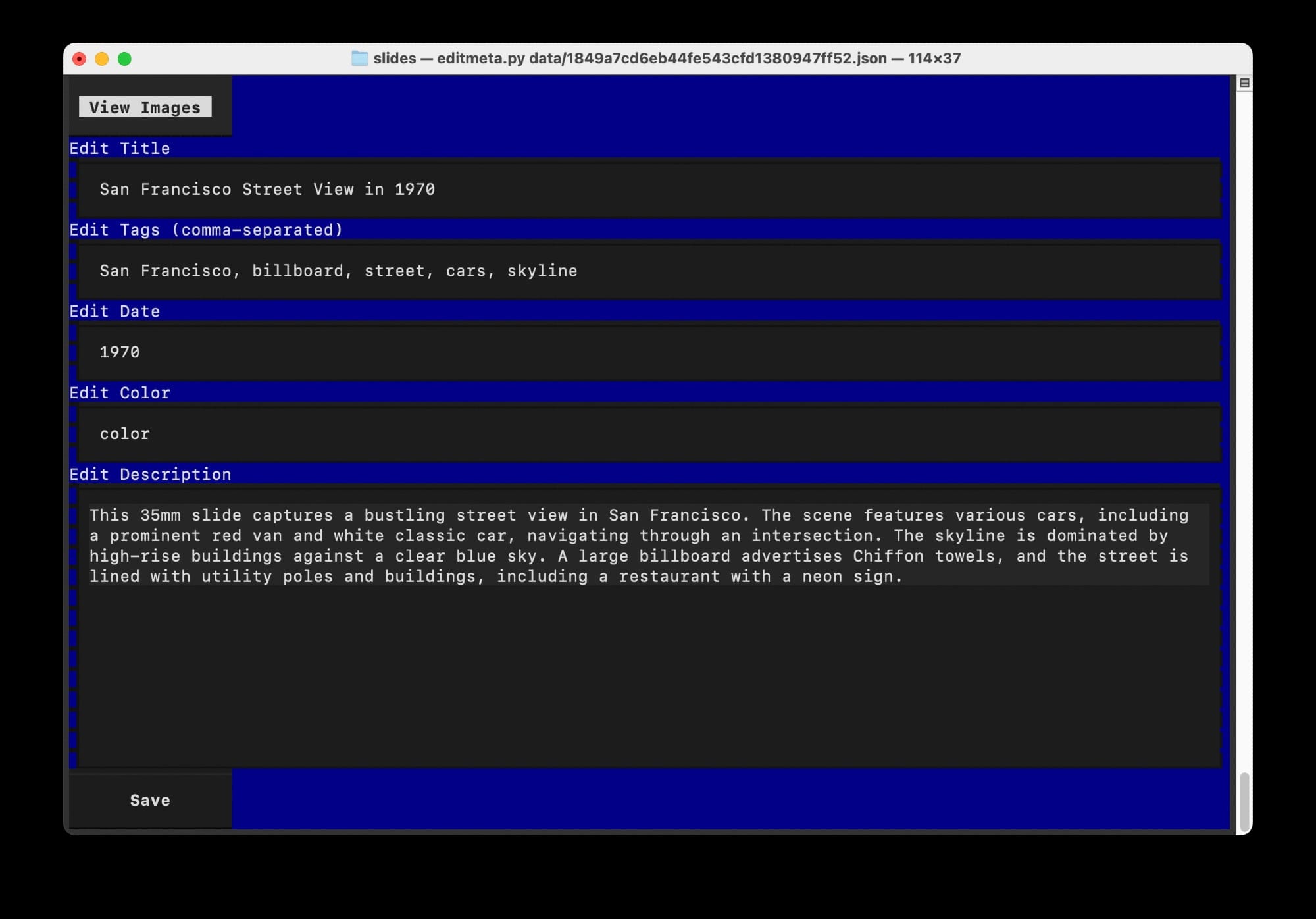
The automatic tagging makes discovery on The Internet Archive possible. Writing descriptions for each image would be labor-intensive but thankfully qwen3-vl:32b seems to be “eh, good enough” for this sort of thing. I do hand-edit the generated descriptions before they are published using a custom metadata editor that runs in the terminal:
The slides are archived in a box with a number on it (“4”) that corresponds to a same-named folder on my Mac (“004”). Folders typically contain:
- Full-size un-edited TIFF files
- JPEG images saved at 1920x
- Any available metadata is saved in a text file or, if bought from eBay, a webarchive file of the auction page

The images have been shared with a Universal Creative Commons license.

If you would like a high-resolution scan or even an original slide, contact me: harrison.page@harrison.page
Scripts for posting the images to social media and The Internet Archive are available here: github.com/harrisonpage/slides